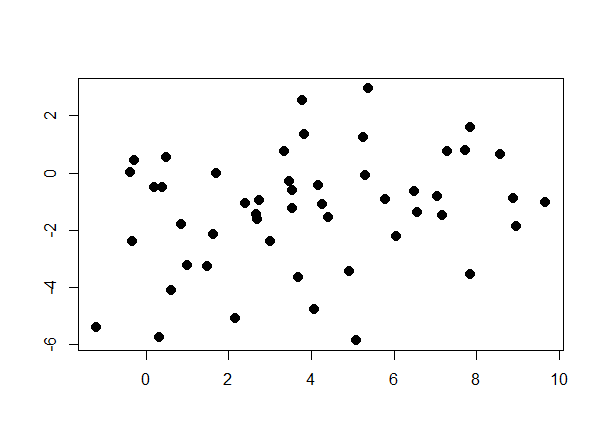In recent decades, while tensor data have gained popularity in modern science, their high-dimensional structures often pose challenges for statistical analysis, specifically in model-based clustering. Model-based clustering is a statistical approach to data clustering, where observed data is considered to have been created from a finite combination of component models, such as the Gaussian mixture model (GMM). Since the formalization of the expected-maximization (EM) algorithm by Dempster et al. (1977), the EM algorithm has been widely employed in the majority of model-based clustering applications. While the GMMs can be readily extended to higher-order tensors using the standard EM algorithm, their performance can be further enhanced by integrating the Doubly Enhanced EM algorithm (DEEM), as proposed by Qing Mai and Deng (2022). Mai et al. consider a tensor normal mixture model (TNMM) that incorporates tensor correlation structure and variable selection for clustering and parameter estimation. They developed the DEEM algorithm which enables DEEM to excel in high-dimensional tensor data analysis. Similar to the EM algorithm, DEEM carries out an enhanced E-step and an enhanced M-step.
In this blogpost, we first introduce the DEEM methods with intermediate steps for the theoretical explanation. The objective is to break down the steps, making the derivation more accessible for our readers to follow. Subsequently, we will conduct a simulation study to evaluate the performance of DEEM.
Before delving into DEEM, we would like to review the EM algorithm and its functioning in clustering.
The EM algorithm is an iterative approach that cycles between two steps for maximum likelihood estimation in the presence of latent variables. The observed data Y is incomplete and data Z is missing. The first step is to write down the joint likelihood, , of the “complete” data . The “E” step of the EM algorithm is to compute the conditional expectation of log-likelihood, , given Y, assuming the true parameter value is
In the “M” step, we maximize with respect to with fixed. We repeat the E step and M step until convergence.
The EM algorithm is well-known for its use in unsupervised learning problems such as clustering with a mixture model. The process from Yang et al. (2012) goes as follows:
Let’s consider a simple example. Suppose we have data as shown in Figure 1, which comes from two distinct classes. We use this data to build a Gaussian model for each class. Since we don’t know which class each observation belongs to, there is no straightforward way to construct two Gaussian models to partition the data. Therefore, we begin with a random guess of our Gaussian model parameters: .
We have ‘missing’ data points that we believe belong to either of the two distributions. After initializing two random Gaussian models, we compute the likelihood of each observation, , being expressed in both of the Gaussian models. The next is the E-step, where we compute the probability that each can belong to any of two distributions. Now we have each point’s probability of belonging to either distribution.
In the M-step, we update the parameters, , of the model to their most likely values. For the new , we take a weighted average of all the points, weighted by the probability that they belong to the first distribution. Denoting is the probability that belongs to the first distribution.
The new can be updated similarly.
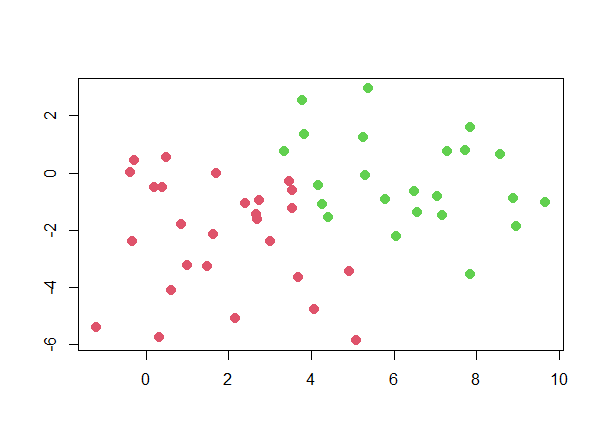
We repeat this process for and and update our distributions. We iterate through the E-step and M-step until convergence, obtaining two clusters as shown in Figure 2.
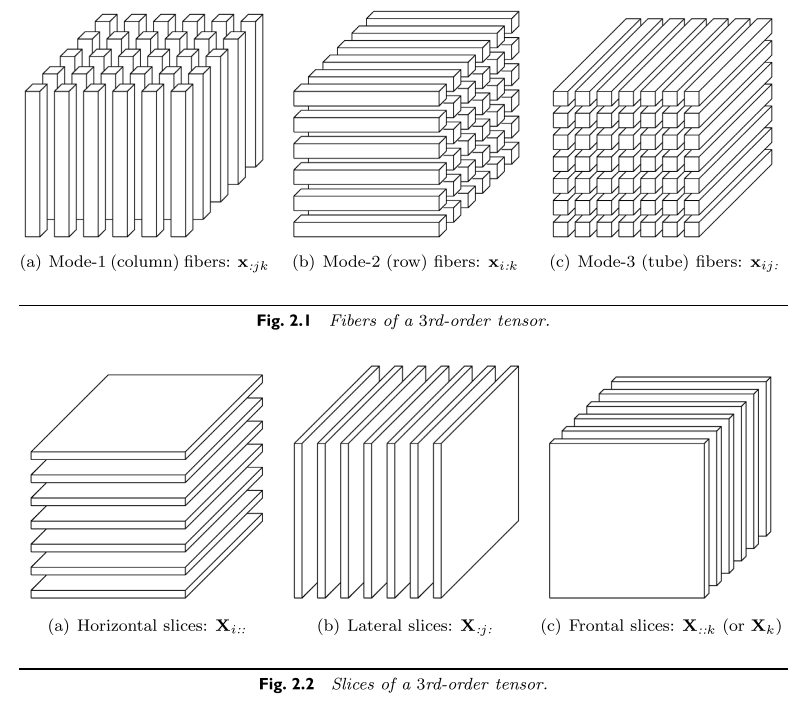
While the term “tensor” might sound unfamiliar to some, tensors are simply multi-way arrays. Data is often structured as matrices, and they are in fact second-order tensors. When we use the term “tensor,” we usually mean tensors of third- and higher-order. The “order” means the dimension of a tensor, and it is sometimes called the “mode.” You can think of a third-order tensor as a cube. As shown in Figure 3, a tensor can be manipulated similarly as a matrix. In a matrix, we can talk about rows and columns. In a third-order tensor, we can talk about fibers when you fix two modes and keep all values of one mode. The index is then the mode that has all the values. Slices are when you fix one mode and keep all values for the rest of the modes. The index is then the mode that is fixed.
Before we continue onto the DEEM algorithm, some concepts and notations are necessary to understand derivations in the following section. Note that the following notations are taken from Kolda and Bader (2009). First of all, we should go over the concept of matricization. If we want to matricize a third-order tensor, we can think of cutting a cube into slices and putting the slices side-by-side to make them into a matrix. We now borrow an example (Example 2.1) given in Kolda and Bader (2009) to demonstrate how to matricize a third-order tensor :
The three mode- unfoldings/matricizations are then
The example above shows that mode- unfolding is to put and side-by-side and mode- unfolding is to stack on top of each other.
This concept is intuitive but much more awkward when we want to define it formally. In Kolda and Bader (2009), the mode- matricization of a tensor is denoted by , which is a matrix of the dimension . (The first dimension comes from the dimension of mode , and the second dimension comes from the product of all the other dimensions.) The tensor element is mapped to the matrix element in the following manner:
Next, the notation is defined as:
where are matrices and and are tensors. The symbol means -mode (matrix) product of a tensor and the matrices . is then a tensor of the dimension . We can write the elements of as:
Also, for any two tensors and in , we define their inner product by
With that, we are ready to learn about the DEEM algorithm. If you are interested in knowing more about tensors, Kolda and Bader (2009) has lots of great details. So be sure to check it out!
In this subsection, we introduce the doubly enhanced EM (DEEM) algorithm and discuss its theoretical properties. Algorithm 1 from Qing Mai and Deng (2022) is provided in the Appendix as our Figure 6.
Let denote the random tensor in such that every element in is distributed as iid . Then we say that a random tensor has a tensor normal distribution, denoted by , if , where is the total mean and each means the covariance matrix within th class. In other words, a tensor normal regression is multivariate normal distribution generalized to a high dimension. An order random tensor has a total of means and covariate matrices each of the dimension for . We can find that the density of has the form
|
| (1) |
where and .
We will consider independent tensor-variate observations in drawn from clusters with the same within-class covariance matrices; suppose that ’s are the mean tensor of the th cluster. Let be the probability of an observation to be taken from the th cluster.
Then the sample from a mixture of the tensor normal distributions can be written as the following:
or equivalently,
|
| (2) |
Hence, indicates the number of the cluster from which was taken, and if is given, has the tensor normal distribution with the mean of the cluster and the within-class covariance matrices . (Recall we assume that the clusters have the same within-class matrices.)
Suppose that is a sample from the model (2). Let denote the set of all parameters in the model. If we can observe , then the complete log-likelihood can be obtained as follows:
But, in general, we cannot observe ; hence, from an initial value , we create a sequence through the E-step to obtain the function
where
|
| (3) |
and the M-step to update the parameter
Then the EM sequence converges to the MLE, but there are some issues in our situation: Getting the updates for and is quite easy and straightforward, but it is challenging to obtain the updates for the covariance matrices . When we compute in (3), all the elements in are used, and the standard EM algorithm does not involve a process for variable selection. Thus, due to an excessive number of parameters in the model, it may lead to the accumulation of errors, which potentially results in inaccurate estimates.
To overcome these problems, we introduce the enhanced E-step, where we replace with an estimator that can be calculated relatively faster under the sparsity assumption. We want to find the objective function that has a better property than the standard function above. First, it can be seen that
|
| (4) |
and
|
| (5) |
for , where
Note that we are considering the clustering problem, that is, we are interested in recovering ’s and finding a method that minimizes the clustering error. It can be shown that the covariance matrices are nuisance parameters in the optimal clustering rule, i.e., the values of are not used in the optimal clustering rule if we already know ’s. To cover more general cases, we do not impose conditions on . Instead, we assume the sparsity condition on ; for , where denotes an index of the tensor, we impose the condition for almost every . In other words, if , then we assume that the number of elements in is significantly smaller than . This assumption comes from the belief that, in the high-dimensional setting, most of the variables are not significant in estimation. The above expressions for show that this assumption reduces the computational cost and improves the estimation efficiency.
If we accept the fact that minimizes the quantity
then it is reasonable to obtain the sequence of estimates by solving the optimization problem
where we added the lasso penalty term to satisfy the sparsity assumption to some extent. Using these , we can obtain the sequence by replacing the parameters in (4) and (5) with their estimates. Then, the objective is defined using as follows:
In light of the sparsity assumption, can be computed based on the values of relatively smaller variables.
In M-step, the parameters can be updated inductively from the proposed function: The estimates for and can be obtained by the formula
Then given , we calculate the intermediate covariance matrices
and the conditional variance of
The target covariance estimator is given by scaling the intermediate covariances with and :
The general process is summarized in Algorithm 1 in the Appendix as our Figure 6.
Now we are interested in how this sequence of parameters behave. In fact, under some initialization condition, it can be seen that there are some constant and such that for large , with a probability ,
where and is a measure of the difference between the initial value and the true parameter . This result implies that if the number of iterations is large, the DEEM estimator converges to the true parameter . Here, the condition means the sparsity assumption.
We consider the error rate of DEEM and the optimal clustering rule:
where denotes the permutation operator and . Here, the optimal clustering rule is optimal in the sense that it minimizes the clustering error. From the result above, we can show that if is large, then with probability
Consequently, this result shows that the error rate of DEEM converges to the error rate of the optimal clustering rule if is large.
For our simulation studies, we follow the framework used in Qing Mai and Deng (2022). For each setting, denotes the number of mixture groups, and noise is generated as a -order tensor:
|
| (6) |
For mixture groups, the is given as a given plus the noise above. For mixture group, the values are simply the noise. Qing Mai and Deng designate two types of :
The covariance matrices are not sparse if they are set using the two formats above. For each setting, we generate independent datasets, the same number of replicates as used by the authors, and present the mean error rate and standard deviation.
The settings are provided in Table 1. Note that, for , the indices not included in the subscript is . In other words, is a sparse tensor. Both the DEEM and EM algorithms require to be given. is a tuning parameter for regularization; however, due to the long computation time, we experiment with several different values of and set it at instead of tuning it for each setting. We encourage interested readers to try out two functions–tune_K and tune_lambda–in the R package TensorClustering.
We choose four settings from the seven settings, because these settings are increasingly more computationally expensive, and we believe that they demonstrate the advantage of the DEEM algorithm compared to the classical EM algorithm in terms of accuracy, as shown in Table 2. We also run three extra settings, which we call M8, M9, M10 to avoid confusion with the seven settings in the paper. The results for these extra settings are shown in Tables 4 and 5.
Note that it is as straightforward to calculate the mean error rate for a clustering problem as it is for a classification problem. Both methods return labels for the groups; however, the group labels do not matter. For example, if there are five observations and their true group labels are and the methods return , the error rate should be . In the paper, the authors explain that the mean clustering error rate is calculated by:
We create a function to permute the true labels, compare the estimated labels and the true labels, and return the lowest error rate. To compare the speed of the two methods, we also record the computation time. Tables 3 and 5 provides the mean computation time and standard error (in parentheses) for each setting.
For the DEEM algorithm, we use the function DEEM; for the standard EM algorithm, we use the function TGMM. Both functions are from the R package TensorClustering. We use the Trnorm function from the R package Tlasso to generate tensor noise with designated covariance matrices. We use the permutations function in the gtools package to permute true labels. In short, be sure to install the three R packages: TensorClustering, Tlasso, and gtools if you would like to reproduce our simulation.
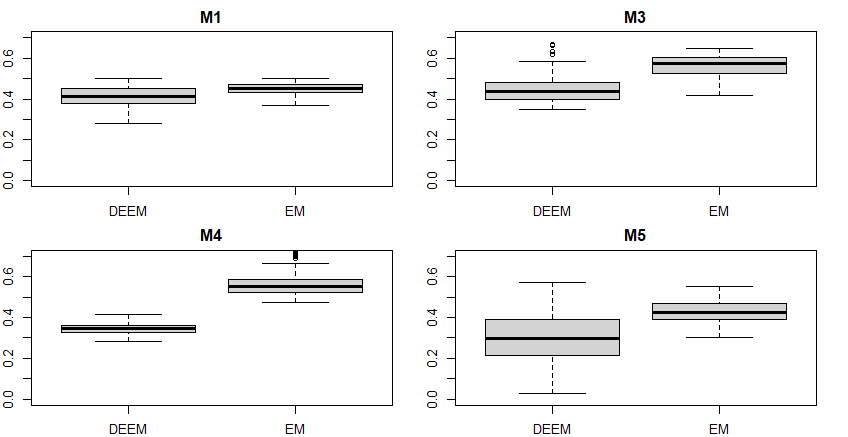
The error rates and computation time are shown in Tables 2 and 3. It is clear that DEEM has lower mean error rates in all four settings. The error rates are in general higher than those given in the article, possibly because the hyperparameters are not tuned for each setting in our case.
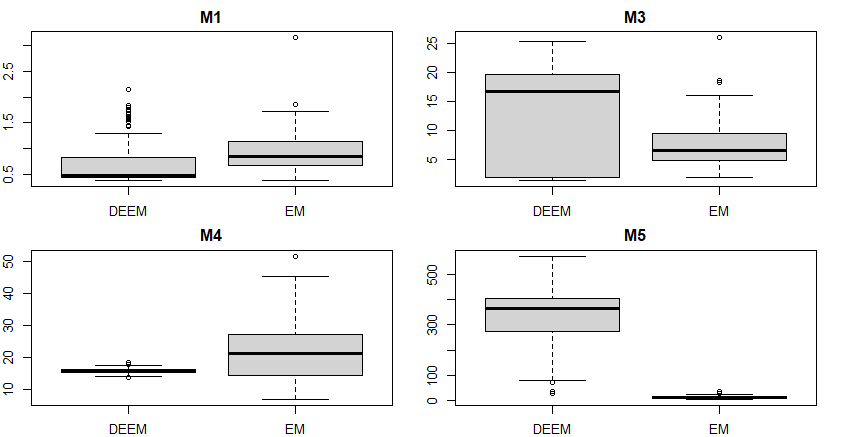
The computation time tells a different story, however. As seen in Table 3, DEEM is not always the winner in terms of time. As the setting becomes more complicated and estimating the clusters becomes more challenging, it takes longer for DEEM to converge. For setting M5, it is possible that DEEM reached the maximum iterations for some runs.
Next, we transform the values in the tables into figures. As shown in Figure 4, DEEM always has lower mean error rates. However, as the model becomes complicated, DEEM’s error rates become more varied, even though the mean rate is still lower. In Figure 5, the story seems more complicated. (Note that we cannot use the same y-axis for all four plots, because the computation time for DEEM for M5 is so long, which would make some of the boxes very small and not informative.) For the two settings M1 and M4, DEEM has a lower computation time. For M3, the computation time for DEEM is much more varied, and EM has an overall shorter computation time. For M5, DEEM has a very long computation time; in fact, the 100 replicates took almost 10 hours. It is unclear if the reduced error rate is worth the computational cost.
In terms of the extra settings, we noticed that the error for DEEM is much lower than EM for M8, for which we set two clusters with the covariance matrices to have a moderate correlation. For M9, we let the setting be an easy case, since the covariance matrices are all identity matrices, and DEEM still has a much lower mean error rate than EM. For M10, we use a fifth-order tensor and make the estimating task an easy one. As seen in Table 4, DEEM has a much lower mean error rate than EM, although its computation time is again quite long.
One recurrent problem from the simulation is that DEEM has a much longer running time than EM. We leave this question about DEEM’s computation time to interested readers.
In this blogpost, we review a new method proposed by Qing Mai and Deng (2022), which is essentially an upgraded version of the classical EM algorithm. This new method, DEEM, tends to have lower error rates on tensor data. However, despite the paper’s claim that the enhanced M step in the DEEM algorithm facilitates fast covariance estimation, we have encountered situations where the running time could be prohibitive. While DEEM proves to be efficient and effective in handling tensor data, there remains potential for further enhancement.
Dempster, A., Laird, N. and Rubin, D. (1977) Maximum likelihood from incomplete data via the em algorithm. Journal of the Royal Statistical Society, 39, 1–22.
Kolda, T. G. and Bader, B. W. (2009) Tensor decompositions and applications. SIAM Review, 51, 455–500. URLhttps://doi.org/10.1137/07070111X.
Qing Mai, Xin Zhang, Y. P. and Deng, K. (2022) A doubly enhanced em algorithm for model-based tensor clustering. Journal of the American Statistical Association, 117, 2120–2134.
Yang, M.-S., Lai, C.-Y. and Lin, C.-Y. (2012) A robust em clustering algorithm for gaussian mixture models. Pattern Recognition, 45, 3950–3961.